
Table of Contents
Bittensor Subnet 14 on Monday launched as Cacheon, a new decentralized competition designed to optimize large language model inference as the economics of serving AI models increasingly becomes a bottleneck for the industry.
Announced this week, Cacheon allows developers to submit containerized inference servers that compete in live evaluations, with rewards going to the fastest systems that preserve model correctness. Instead of focusing on improving model intelligence itself, the subnet is designed to tackle a growing challenge across AI infrastructure: how to serve models faster, cheaper, and at production scale.
"Model training is like designing a Formula 1 race car. Inference serving is like running the pit crew and race strategy." - Cacheon
The launch arrives as frontier AI model quality begins to converge, shifting greater attention toward inference performance. Every chatbot, autonomous agent, and enterprise AI workflow depends on serving tokens efficiently, where lower latency, higher throughput, and lower cost per request can materially impact both user experience and unit economics.
How Cacheon Works and Why Inference Matters
As leading AI models become increasingly competitive with one another, infrastructure efficiency is emerging as one of the most important economic variables in AI deployment.
As such, Cacheon turns inference optimization into an open competition where developers compete to build faster serving infrastructure for large language models without sacrificing output quality.
Participants submit containerized inference servers that are benchmarked against a standardized vLLM baseline running on identical hardware. Systems are evaluated on metrics including response latency and token generation speed, while validators also verify that submissions preserve the original model’s outputs. Servers that attempt to improve speed by altering correctness are disqualified.
Training a frontier model may require enormous computational investment, but serving that model at scale introduces a separate set of challenges. Every chatbot response, AI agent action, or enterprise workflow depends on inference infrastructure that can deliver tokens quickly and economically under real-world demand.
Cacheon frames that problem as a market-driven optimization challenge. Instead of relying on a centralized engineering team, the subnet creates a competitive environment where developers continuously attempt to outperform one another on standardized infrastructure.
The team’s long-term goal is to make inference improvements discoverable, measurable, and deployable in the open. Over time, Cacheon plans to expand beyond its initial benchmarking environment into additional optimization techniques, models, and serving configurations.
Next Up for Cacheon
Cacheon’s mainnet is expected to go live by May 19 and the network has already begun testing. According to the team, its first testnet evaluation round recently concluded, with early miner submissions failing startup and model-loading requirements, a normal part of the early testing process.
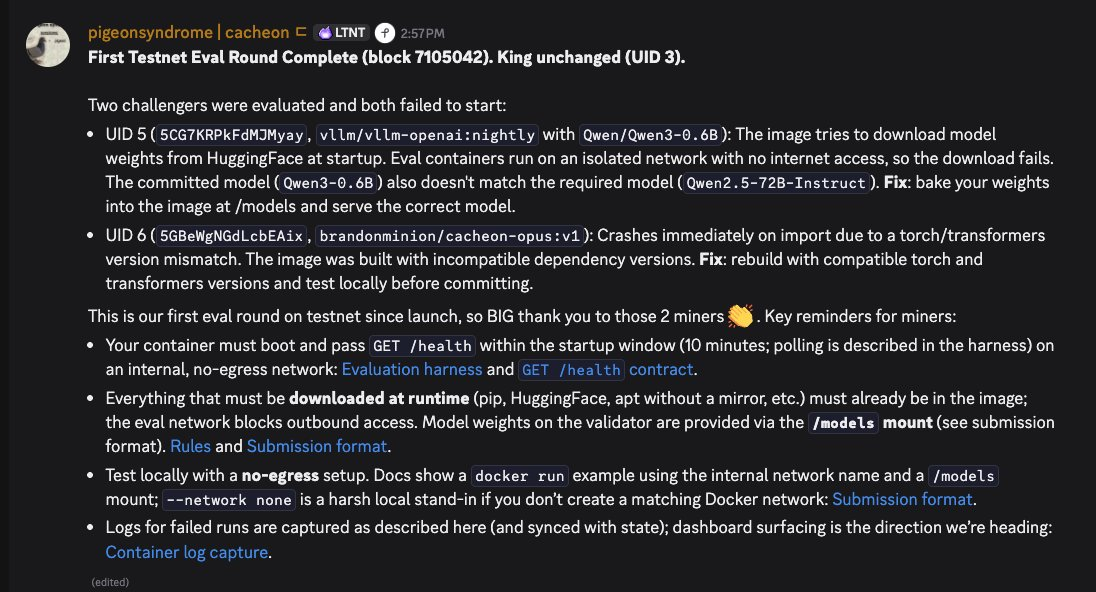
Looking ahead, Cacheon plans to expand beyond a single fixed benchmarking environment.
Future iterations could introduce additional optimization techniques, more models, and broader serving environments with the goal of turning high-performing submissions into production-ready inference infrastructure.
Disclaimer: This article is for informational purposes only and does not constitute financial, investment, or trading advice. The information provided should not be interpreted as an endorsement of any digital asset, security, or investment strategy. Readers should conduct their own research and consult with a licensed financial professional before making any investment decisions. The publisher and its contributors are not responsible for any losses that may arise from reliance on the information presented.






{kind=link}