
Table of Contents
Chutes is entering what it describes as a new phase of growth, one focused on building a sustainable business around decentralized AI inference.
In a newly published article titled “Chutes: a glance behind, and a leap ahead,” Chutes core contributor and backend developer Jon Durbin reflected on the platform’s progress over the past year while outlining the infrastructure, monetization, and model training priorities now shaping its roadmap.

Durbin said one of Chutes’ original goals was to help bring Bittensor into the hands of a broader AI audience, arguing that while the network had shown strong technical progress, usage outside of Bittensor itself had remained limited.
“Chutes broke that cycle and unleashed the power of bittensor in a pretty huge way,” Durbin wrote.
One of the platform’s early milestones, according to Durbin, was reaching roughly 160 billion LLM tokens in a single day using permissionless decentralized compute. While the service was free at the time, he argued the achievement demonstrated that decentralized infrastructure could support production-grade AI workloads despite challenges including DDoS attacks, GPU validation, node dropout, and maintaining high availability.
Since then, Durbin said the focus has shifted toward building what he described as a “sustainable flywheel” capable of driving long-term value for both Chutes and Bittensor.
This transition comes as the GPU market has tightened considerably. Durbin wrote that Hopper and Blackwell GPUs have become harder to source and more expensive, while hourly spot pricing has become increasingly rare. In response, Chutes has focused on narrowing the gap between platform revenue and miner emissions while maintaining hardware availability and service reliability.
Despite reducing inventory by nearly two-thirds since December, Durbin said Chutes has held revenue stable and increased monetization efficiency in recent months.
“Token numbers have indeed decreased, but the dollar per token in revenue is actually the metric we are concerned with,” he wrote. “We are driving that number up daily.”
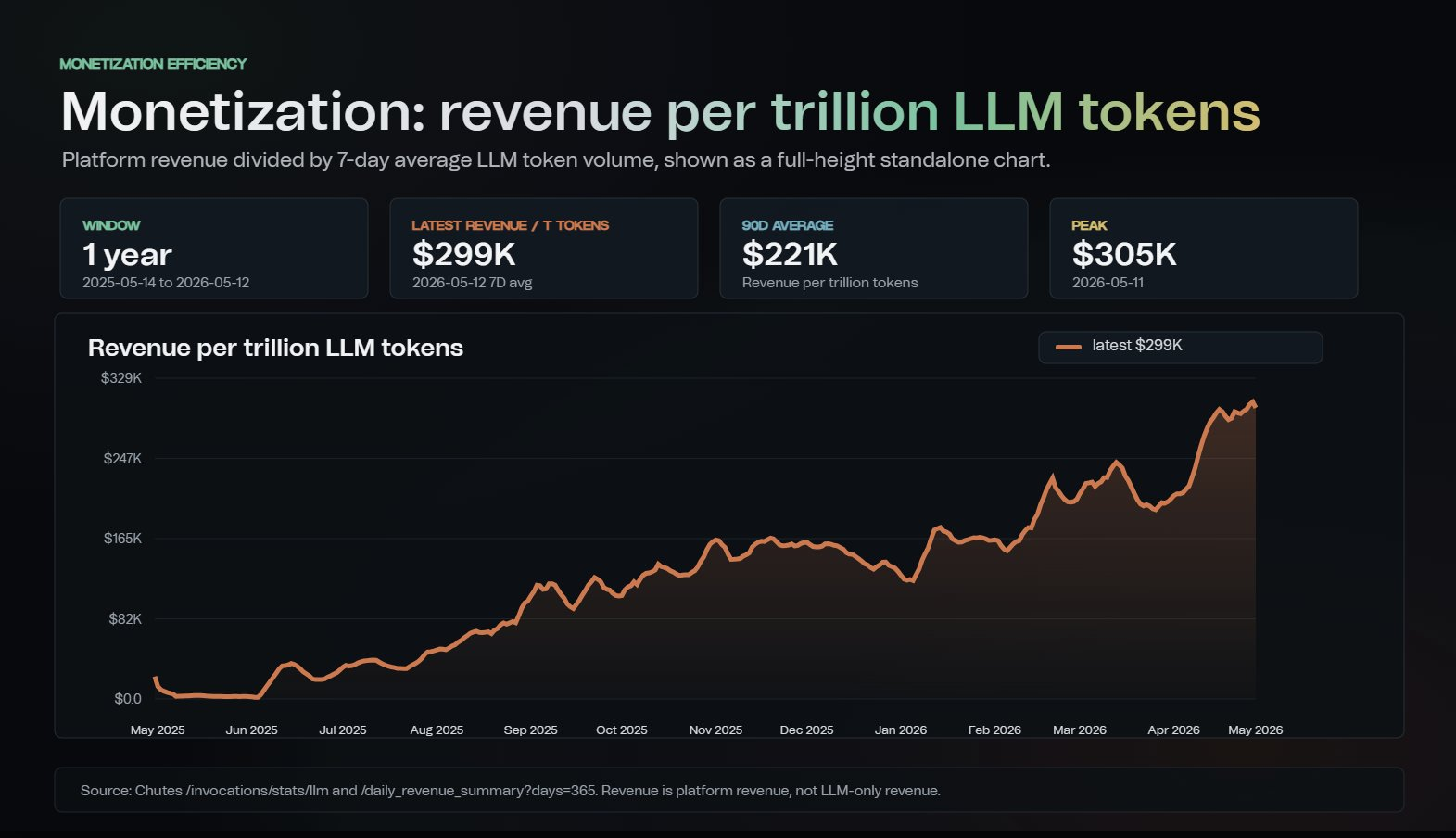
Metrics shared by Durbin show revenue generated per trillion LLM tokens rising steadily over the past year, with recent 7-day averages approaching $300,000. Durbin argued that improving monetization efficiency, rather than maximizing token throughput, has become the more important benchmark as GPU supply tightens and costs increase.
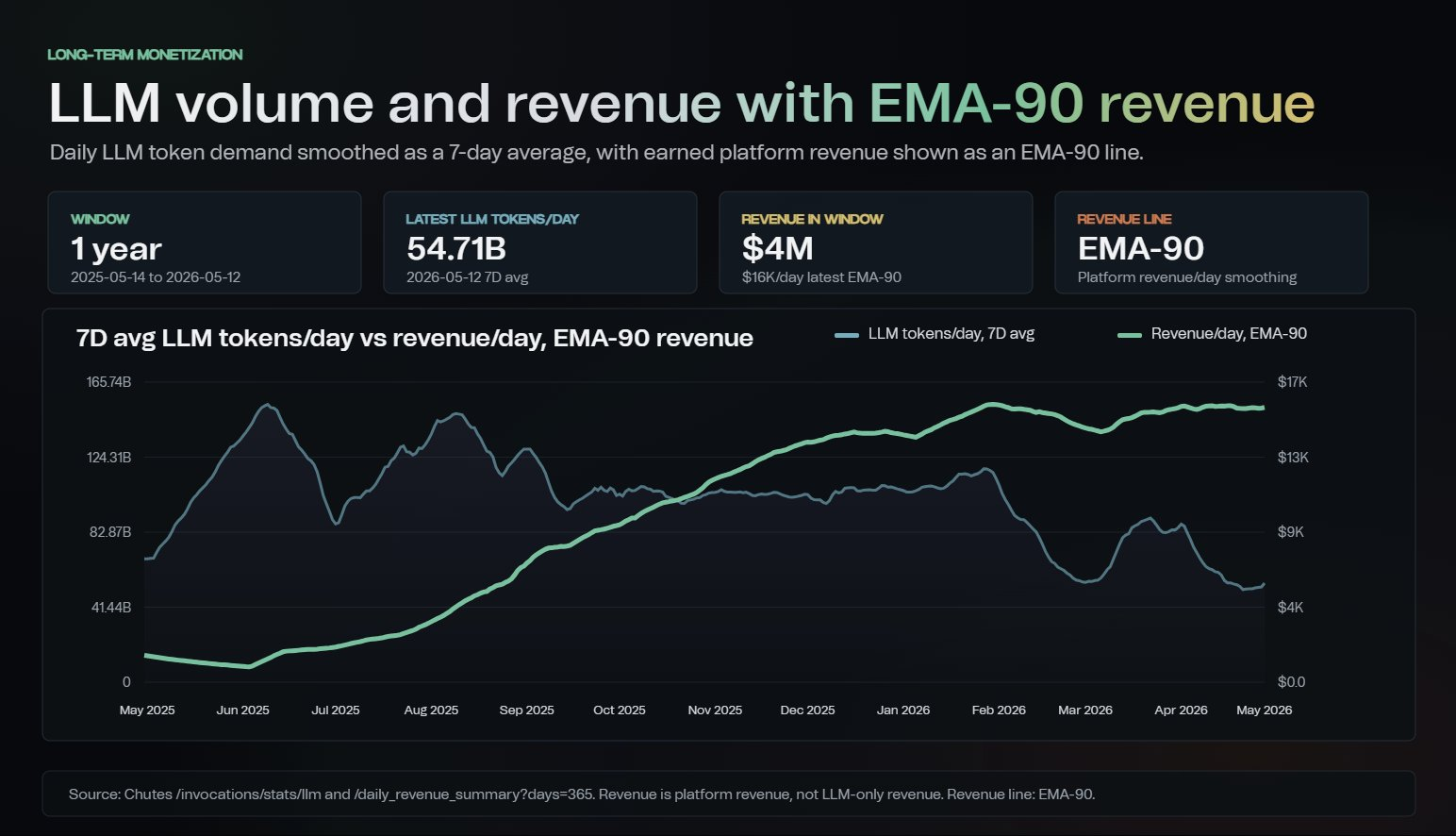
A second chart shared in the post shows daily LLM token demand declining from earlier highs while Chutes’ smoothed revenue line remained stable and continued trending upward over time. Durbin attributed this to a combination of pricing changes, infrastructure optimization, and a greater emphasis on models and workloads that justify their compute costs.
According to Durbin, Chutes has also begun removing models that “don’t earn their keep” in an effort to free up capacity for more heavily used services and reduce platform congestion. At the same time, the team is onboarding new compute providers and building a mining pool feature intended to expand and stabilize capacity as demand grows.
“We've been compute constrained,” Durbin wrote. “Demand is there, supply needs to match it.”
Chutes Bets on More Efficient AI Training
Beyond infrastructure economics, Durbin said Chutes is increasingly focused on a longer-term challenge facing AI broadly: the growing shortage of compute required to train and serve frontier models.
“The world is hungry for tokens, and starving for GPUs to serve them,” Durbin wrote.
According to Durbin, Chutes is not pivoting away from inference toward becoming a dedicated model training subnet. Instead, he described the work as complementary to the platform’s existing business, focused on developing more efficient AI systems that require less compute to train and run.
Durbin argued that many of today’s most popular models have become so large that they barely fit on high-end server configurations and require enormous computational resources. Instead of continuing to scale hardware requirements upward, he said the goal is to design models that can reduce VRAM requirements, improve inference speed, and deliver greater throughput per GPU.
“Distributed training isn't the goal; it's merely a means to an end,” Durbin wrote. “The end is super efficient, compact, excellent models with fully open source training formulas/datasets/etc.”
Durbin said he plans to publish a whitepaper and early research related to a new training method called “Parallax,” which he described as a potential breakthrough for decentralized training, particularly for Mixture-of-Experts (MoE) models.
According to Durbin, early experiments involving a 20 billion parameter model trained over the internet using single GPUs per “composer” showed a performance gap of roughly 1.5% or less compared with traditional end-to-end training. He added that, with sufficient training steps, the gap could potentially close further.
The approach, he wrote, could also allow portions of training workloads to be distributed onto commodity hardware, including consumer GPUs and even laptops, while reducing compute requirements per token. For Durbin, the broader objective is not decentralized training for its own sake, but addressing what he sees as a widening mismatch between AI demand and available compute.
“The CAPEX on model training/datacenter build out is absolutely staggering,” he wrote, arguing that decentralized approaches are increasingly becoming “more of a requirement than an option” as infrastructure bottlenecks intensify.
Chutes Moves Toward Fully Secure Infrastructure
Alongside its training research, Chutes is also working to improve inference performance and privacy across the models it already serves.
Durbin said the platform is implementing a range of inference optimizations designed to improve efficiency while maintaining compatibility with Trusted Execution Environments (TEEs), which isolate workloads in secure computing environments.
According to Durbin, privacy requirements limit some traditional optimization methods. Rather than relying on plaintext distributed storage systems, Chutes is implementing encrypted approaches including ephemeral file-based encryption local to TEE virtual machines and RAM-based caching methods designed to preserve security protections.
Durbin also said Chutes is nearing the completion of a research effort with Harvard University professor Juncheng Yang focused on analyzing cache hit rates and routing methodologies. He said the findings could unlock what he described as effectively “free” performance improvements by improving request routing across infrastructure.
At the infrastructure level, Chutes is accelerating a transition toward 100% TEE-only infrastructure, even if the migration temporarily reduces availability for some models.
“While it may cause a bit of instability and lack of availability for a short time, we believe the privacy, security, and validation benefits far outweigh any downside,” Durbin wrote.
The move, he said, could reduce validator costs by eliminating the need for GPU instances to run GraVal, while allowing the team to spend less time combating exploiters and more time improving the platform.
What Comes Next for Chutes
For Chutes, Durbin framed the platform’s next phase as one centered on sustainability: improving revenue efficiency, expanding compute supply, optimizing inference, and developing models that can do more with less hardware.
Rather than maximizing token throughput alone, the roadmap outlined in the post emphasizes durability. That includes increasing pricing closer to market rates, removing underutilized models, onboarding new compute providers, and building a mining pool feature designed to stabilize capacity over time.
At the same time, Chutes is continuing to invest in longer-term research aimed at reducing the amount of infrastructure AI systems require in the first place. Through its proposed “Parallax” training method and ongoing inference optimizations, Durbin argued the future of AI may depend less on endlessly scaling compute and more on making models fundamentally more efficient.
While many of the initiatives outlined remain in progress, the post offers a detailed look at how Chutes is approaching the realities of a more constrained GPU market, where hardware availability, economics, and performance increasingly matter as much as raw demand.
For Bittensor, the update provides a glimpse into how applications built on decentralized compute are evolving beyond experimentation and toward operational sustainability, even as the infrastructure challenges facing AI continue to intensify.
“Overall we're more excited about where Chutes is going than we have ever been!” Durbin wrote. “Onwards, and upwards!”
Disclaimer: This article is for informational purposes only and does not constitute financial, investment, or trading advice. The information provided should not be interpreted as an endorsement of any digital asset, security, or investment strategy. Readers should conduct their own research and consult with a licensed financial professional before making any investment decisions. The publisher and its contributors are not responsible for any losses that may arise from reliance on the information presented.








{kind=link}