Table of Contents
Templar has completed the largest decentralized large language model training run to date, building a 72-billion-parameter AI model using a global network of independent contributors instead of a traditional data-center cluster.
The model, called Covenant-72B, was trained on roughly 1.1 trillion tokens across Bittensor subnet 3, a decentralized AI network where anyone with GPUs can contribute compute power.
We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3.
— templar (@tplr_ai) March 10, 2026
72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely.
1/n pic.twitter.com/W0Ks563Cld
Unlike typical AI training runs operated by a single company, Covenant-72B allowed participants to join and leave freely, with no whitelist or centralized coordination.
In simple terms, dozens of independent computers across the internet collectively trained a model roughly the size of leading open-source systems.
The experiment is part of a broader push to decentralize AI development, an area increasingly dominated by large technology companies with access to specialized infrastructure and massive compute budgets.
Training a Large AI Model Without a Data Center
Large language models of this scale are usually trained inside specialized data centers using tightly connected GPU clusters.
Inside those environments, GPUs communicate through ultra-fast networking hardware such as 400 gigabit-per-second InfiniBand between servers and NVLink connections capable of several terabytes per second within a single machine.
Covenant-72B operated under far more limited conditions.
Participants were assumed to have ordinary internet connections, with roughly 500 Mb/s download speeds and 110 Mb/s upload speeds per peer.
That difference creates a major bottleneck. Training large AI models requires computers to constantly share updates about what they have learned. When those computers are scattered across the internet, network bandwidth quickly becomes the limiting factor.
Compressing Training Updates
To make decentralized training possible, the Templar team developed a system called SparseLoCo.
Instead of sharing updates after every training step, each participant performs 30 local optimization steps before sending a compressed update back to the network.
Those updates are heavily reduced in size using several techniques, including:
- top-k sparsification
- 2-bit quantization
- error feedback
Essentially, this means that the system sends only the most important pieces of training information, dramatically reducing the amount of data that must travel across the network.
According to the team, this approach achieved more than 146× compression compared with traditional dense gradient communication.
Even though Covenant-72B is 7.2 times larger than a previous decentralized model known as INTELLECT-1, communication delays during training dropped significantly.
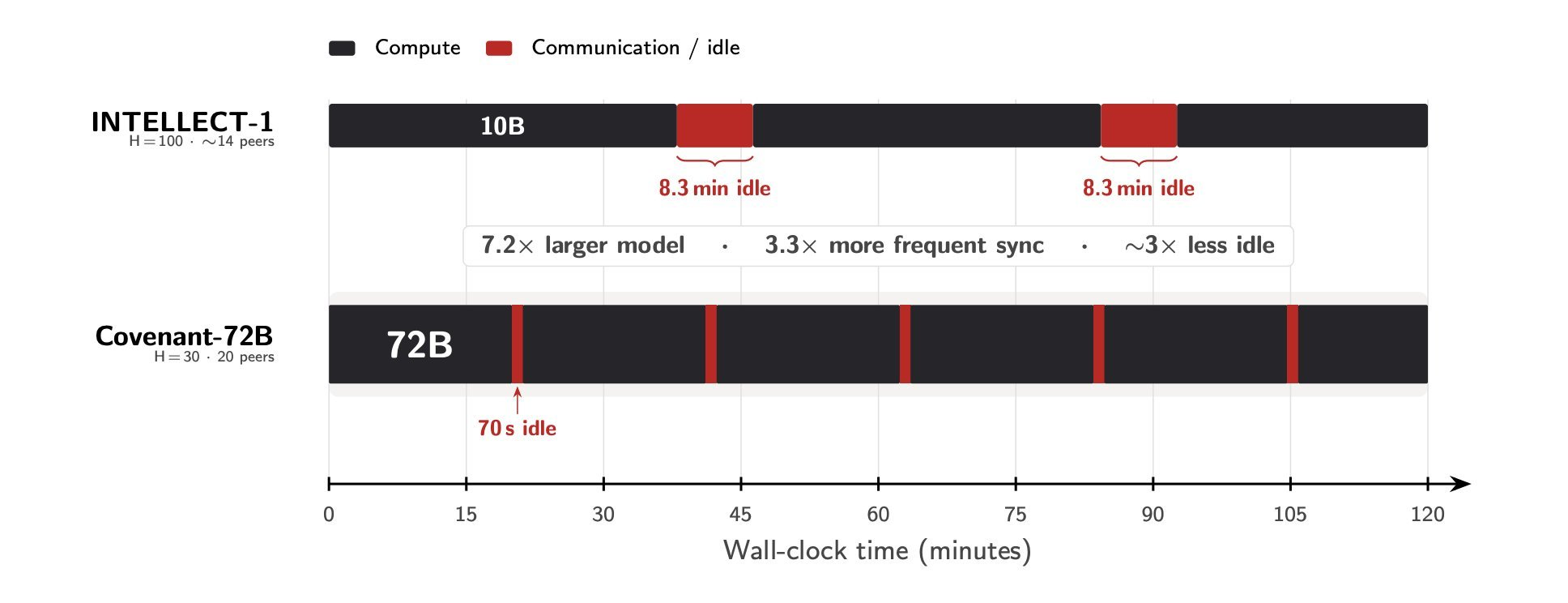
Synchronization rounds resulted in about 70 seconds of idle communication time, compared with roughly 8.3 minutes in the earlier run.
Overall compute utilization reached 94.5%, meaning GPUs spent most of their time actively training rather than waiting for updates from other peers.
A Fully Permissionless Training Network
Beyond bandwidth constraints, the project faced another challenge: maintaining trust in a fully open network.
Previous decentralized training experiments often relied on whitelisting participants before allowing them to contribute compute resources. Covenant-72B instead allowed any node to join or leave the training process at any time.
That flexibility introduces risks. Participants could attempt to submit poor-quality updates, copy work from others, or even attempt to disrupt the model. To address this, the team built a validation system called Gauntlet, which evaluates contributions before they are incorporated into the model.
Gauntlet analyzes each update using several checks, including:
- measuring loss improvements on assigned and unassigned training data
- verifying model synchronization and node activity
- ranking participants using an OpenSkill scoring system
- normalizing update magnitude so no single peer can dominate the model update
The system automatically determines which contributions are accepted into each training round.
Global Contributors Train the Model
Over the full training run, more than 70 unique peers contributed compute resources using different hardware setups across multiple geographic locations.
Participation remained close to the network’s capacity throughout the training process, according to the team.
Tokens used for training represent the basic units of language models, roughly corresponding to words or fragments of words. Covenant-72B was trained on approximately 1.1 trillion of these units of text, placing it in the same scale category as many modern open-source models.
Competitive Results With Centralized Models
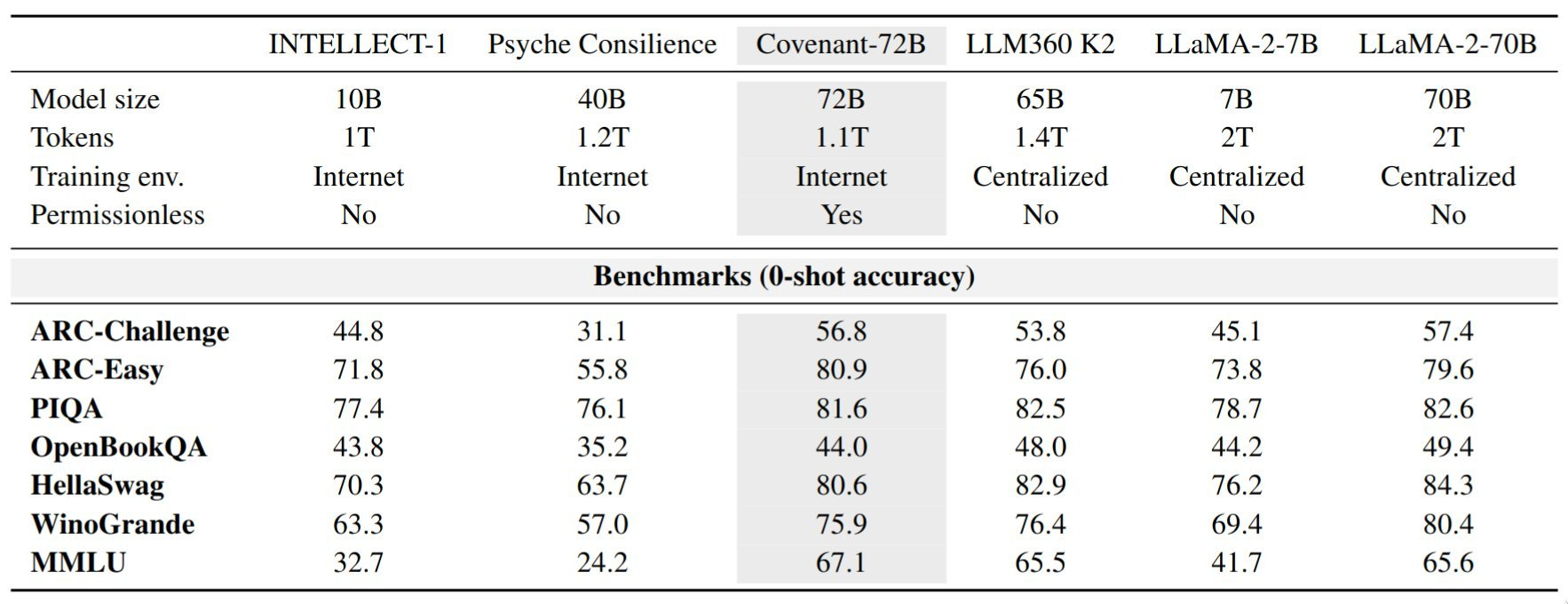
Templar says Covenant-72B performs competitively with well-known open-source models trained in traditional data centers.
On the MMLU benchmark, the model reportedly scored 67.1, outperforming LLaMA-2-70B (65.6) and LLM360 K2 (65.5).
The team also released a chat-optimized version called Covenant-72B-Chat, created through additional supervised fine-tuning that expanded the model’s context window from 2,000 to 8,000 tokens.
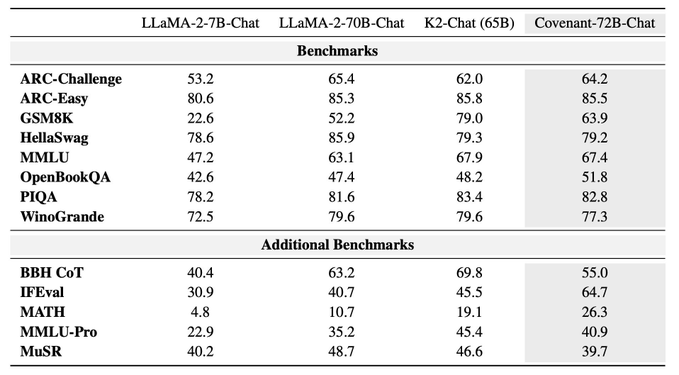
According to the developers, the chat version demonstrated particularly strong performance on instruction-following and mathematical reasoning benchmarks.
A New Model for Training AI
The results suggest that large AI systems don't require centralized infrastructure to train effectively.
By combining heavy communication compression with automated validation of participant contributions, the experiment demonstrates that large language models can potentially be trained across globally distributed compute connected by ordinary internet links.
If the approach continues to scale, decentralized training could allow smaller compute providers to collaborate on building advanced AI systems rather than relying solely on hyperscale data centers.
As the Templar team summarized in its announcement, the main constraint was not physics, but coordination.





{kind=link}