
Table of Contents
In December 2025, Nvidia paid $20 billion for Groq's assets, the largest acquisition in the company's history, to control the hardware and software layer that actually runs AI when users ask it questions.
The deal highlighted that, as inference demand explodes, the companies that own the infrastructure serving AI responses are positioned to capture the economics of the industry. As far as that infrastructure category is concerned, Bittensor stands apart for attempting to coordinate the full AI stack through an open market rather than a centralized company.
In this article, we’ll examine why inference has become one of the most important layers in AI, why rising usage can compress margins for companies renting infrastructure, and how Bittensor built an alternative model where the infrastructure layer is coordinated by an open network rather than controlled by a single company.
Why Cheaper Tokens Made the Bill Bigger
A token is the basic unit of text an AI model reads and writes, roughly three-quarters of a word. When OpenAI launched its first reasoning model, o1, in September 2024, processing one million output tokens cost $60. By January 2025, o3-mini delivered comparable reasoning performance for $4.40 per million output tokens, a 93% price drop in roughly four months. By any normal reading of a technology cost curve, that should have made AI cheaper to run.
Spending went the other direction. On Microsoft's Q3 FY2026 earnings call, CFO Amy Hood disclosed that Microsoft expects to invest roughly $190 billion in capital expenditures in calendar year 2026, with $25 billion of that driven by higher component costs alone. Q3 capital expenditures came in at $31.9 billion, with two-thirds allocated to GPUs and CPUs, and Hood confirmed the company expects to remain capacity-constrained through at least the end of 2026. Across the five largest US tech companies, planned capital expenditures for 2026 run between $660 and $690 billion, consuming nearly 100% of operating cash flows against a 10-year average of 40%.
Jevons paradox helps explain this trend. In 1865, economist William Stanley Jevons observed that making coal-burning engines more efficient didn't reduce coal consumption. Cheaper operation unlocked industries that couldn't afford coal before, and total consumption rose sharply because of the efficiency gains, not despite them. AI compute follows the same logic: 14x cheaper tokens didn't reduce demand, they created an entirely new tier of products far more compute-hungry than anything that preceded them.
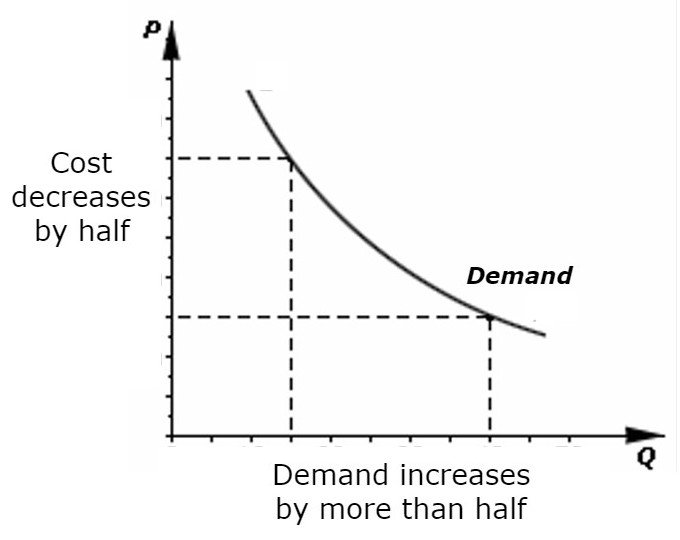
A reasoning model, for example, burns roughly 10x more tokens than a standard model on the same task. An AI agent, a system that loops through multiple steps, calls external tools, and checks its own work, chains roughly 20x the requests of a single question-and-answer exchange. With tokens 14x cheaper but each task consuming 10,000 more of them, total compute spending grows by orders of magnitude.
How Your Margins Disappear as Your Product Succeeds
A company builds a product on a rented AI model, paying a fee for every token users generate. Early on, usage is low and the economics look manageable. Then the product works. Every new session, every agent task is another compute bill the company absorbs before collecting a dollar.
Revenue grows roughly linearly because the company charges a subscription or per-use fee. Faster than that revenue, compute costs compound: AI agents and reasoning workflows consume far more tokens per session than simple chat, and the gap widens with every product improvement. The better the product works, the bigger the structural loss per user.
The KV cache is the part of this that rarely gets discussed. It's the AI equivalent of short-term memory: the system that holds the context of an ongoing conversation or a multi-step agent task in active storage on expensive hardware. A single long agent session holds gigabytes of data per user before generating a response. At thousands of concurrent users, the memory hardware bill alone reprices the entire infrastructure layer.
For companies without Microsoft's balance sheet, the only exit from this trap is to own the compute, the model, and the delivery layer outright, so margin doesn't leak to someone else at every layer of the stack. That option is available to roughly five companies on earth.
How Bittensor Coordinates the AI Stack Through Open Markets
Open-source AI projects hand you a model weight file and leave the infrastructure to you. Bittensor built an incentive system running from raw compute all the way up to application output, with every participant rewarded in proportion to the value they contribute.
The mechanism is called dTAO, short for Dynamic TAO. Each subnet, a specialized AI service on the network, operates its own liquidity pool: a trading pair between TAO, the network's base currency, and that subnet's own Alpha token. Staking TAO into a subnet executes a swap into the pool, pushing the Alpha token price up. A higher price captures a larger share of newly issued TAO from the protocol, so the incentive runs from output quality to capital allocation with no company taking a cut in between.
Within each subnet, emissions split roughly 41% to miners, 41% to validators, and 18% to the subnet owner. Miners run the actual compute. Validators score miner output and set the weights that determine reward distribution, so no miner receives emissions without passing quality review. Founders define the rules: what counts as good output, how miners get scored, and what the network pays for.
What the market has done with this structure is telling. TAO staked across subnets surged from $74,400 to over $620 million in the past year, an 833,000% increase according to CryptoRank. The total market capitalization of all subnet Alpha tokens has surpassed $1.5 billion, with over 70% of TAO's circulating supply currently staked. As of early 2026, the network supports 128 active subnets, each competing for capital by producing better output across inference, storage, training, agents, data, and compute.
For the demand curve, the implications are structural. Every inference request running through a Bittensor subnet generates miner rewards, raises that subnet's Alpha token price, and pulls more TAO into the network's liquidity pools. The same explosion in AI usage that compresses margins on closed platforms is the exact mechanism that deepens Bittensor's subnet liquidity and increases demand for TAO. Closed platforms are structurally punished by rising inference demand. Bittensor is structurally rewarded by it.
The Compute Era Is Starting, Not Peaking
Training dominates coverage of AI infrastructure: the expensive, months-long process of building a model from scratch, spinning up a massive cluster, running it for weeks, then stopping. Inference works nothing like that. It runs every time any user anywhere sends a message to any AI product, scales with every new user, and compounds with every new product category that cheaper tokens make viable.
Every new application that cheaper tokens unlock, whether agents, deep research tools, or persistent memory sessions, generates inference demand that flows somewhere.
On a closed platform, it flows through a pricing desk where one party captures the margin and another absorbs the cost. On Bittensor, it flows through an open market where the protocol routes value to whoever produces the best output, with no intermediary collecting the difference.
An AI Infrastructure Model No Company Controls
Closed AI infrastructure charges you for scale and transfers the margin problem onto you as your product succeeds. On Bittensor, stakers are liquidity providers and underwriters of subnets, with their collective capital allocation driving emissions toward the subnets producing the most value.
Control the full stack or pay rent to someone who does: that's the inference era's winner logic. Every company renting AI infrastructure writes a check that gets bigger as their product succeeds, but with Bittensor, we have the only open network where the stack belongs to no one, with rising demand flowing back to the participants who built it.
Build on a closed API and watch your margins compress as your customers succeed. Stake into Bittensor and watch the opposite happen. Nvidia paid $20 billion for the right to own that layer.
On Bittensor, no one can.
FAQs: Bittensor, AI Infrastructure, and Inference Economics
What is Bittensor?
Bittensor is a decentralized AI network that coordinates compute, models, data, and application outputs through an incentive system powered by the TAO token. Instead of a single company owning the infrastructure, independent participants compete to provide useful AI services across specialized subnets.
Learn more about the basics of Bittensor in our comprehensive guide.
How is Bittensor different from traditional AI companies like OpenAI or Google?
Traditional AI companies typically control the full infrastructure stack, including compute, models, APIs, and pricing. Bittensor operates as an open network where miners, validators, and subnet operators are rewarded based on performance, with value distributed through market incentives rather than centralized ownership.
What is AI inference and why does it matter?
Inference is the process of running an AI model after training, such as generating responses, reasoning through tasks, or powering AI agents. Every chatbot prompt, search query, or agent action creates inference demand, making it one of the fastest-growing cost centers in AI.
Why are AI infrastructure costs rising even as models get cheaper?
AI costs are falling on a per-token basis, but overall spending is rising because lower costs unlock new use cases. Reasoning models, AI agents, and long-context systems consume significantly more compute than traditional chat models, increasing total infrastructure demand. This dynamic is often described through the Jevons paradox.
What is dTAO in Bittensor?
Dynamic TAO (dTAO) is Bittensor’s market-based incentive system. Each subnet has its own Alpha token and liquidity pool, allowing capital to flow toward subnets producing valuable outputs. Higher-performing subnets attract more stake and a greater share of network emissions.
What are Bittensor subnets?
Subnets are specialized marketplaces within Bittensor focused on specific AI functions such as inference, data, training, storage, agents, or compute. Each subnet operates independently while competing for TAO capital and emissions based on the quality of output it produces.
Can Bittensor benefit from growing AI demand?
Bittensor is designed so that increased usage of AI services can deepen network activity and subnet incentives. As more inference requests flow through subnets, miners and validators may receive greater rewards, while capital allocation mechanisms direct resources toward higher-performing services.
Why is inference becoming more important than training in AI?
Training happens periodically to create or improve a model, while inference happens every time users interact with AI. As AI products scale globally, inference demand compounds continuously, making it a critical economic layer for AI infrastructure providers.
Is Bittensor an investment in AI infrastructure?
Bittensor is often discussed as part of the broader AI infrastructure category because it coordinates decentralized compute and AI services. However, participation carries technical, market, and token-related risks, and users should conduct independent research before making financial decisions.
Disclaimer: This article is for informational purposes only and does not constitute financial, investment, or trading advice. The information provided should not be interpreted as an endorsement of any digital asset, security, or investment strategy. Readers should conduct their own research and consult with a licensed financial professional before making any investment decisions. The publisher and its contributors are not responsible for any losses that may arise from reliance on the information presented.







{kind=link}