
Table of Contents
Macrocosmos has announced the launch of Project Orion, unveiling what it describes as the largest distributed large language model pretraining run conducted across the open internet.
According to the team, Orion-100B trained a 100 billion parameter model across 16 pipeline-parallel stages and three replicas using geographically distributed Nvidia A100 GPUs, achieving more than 30% model FLOP utilization (MFU) and roughly 65% of the training speed of comparable datacenter deployments.
The result represents a major milestone for Macrocosmos' IOTA training architecture (and Bittensor at large), which is being developed on Bittensor Subnet 9.
"We believe that this work presents, for the first time, an economically compelling case for training large models using distributed approaches," the team wrote.
Unlike most decentralized training systems, which rely on data-parallel approaches that require every participant to host a full model replica, IOTA uses distributed pipeline parallelism.
The model itself is split across many machines, allowing individual participants to contribute a single GPU while collectively training models far larger than any one participant could host alone.
From 15 Billion to 100 Billion Parameters
The announcement marks the culmination of roughly a year of development.
According to Macrocosmos, the project launched in June 2025 with a 15-billion-parameter target model before scaling back to a smaller 1.5-billion-parameter testbed. Over the following months, the team conducted more than 700 experiments and trained nearly 15 trillion tokens while rebuilding core components of the system.
The chart below shows that progression, including the move from early testing to Orion-100B's 16-stage distributed training configuration.
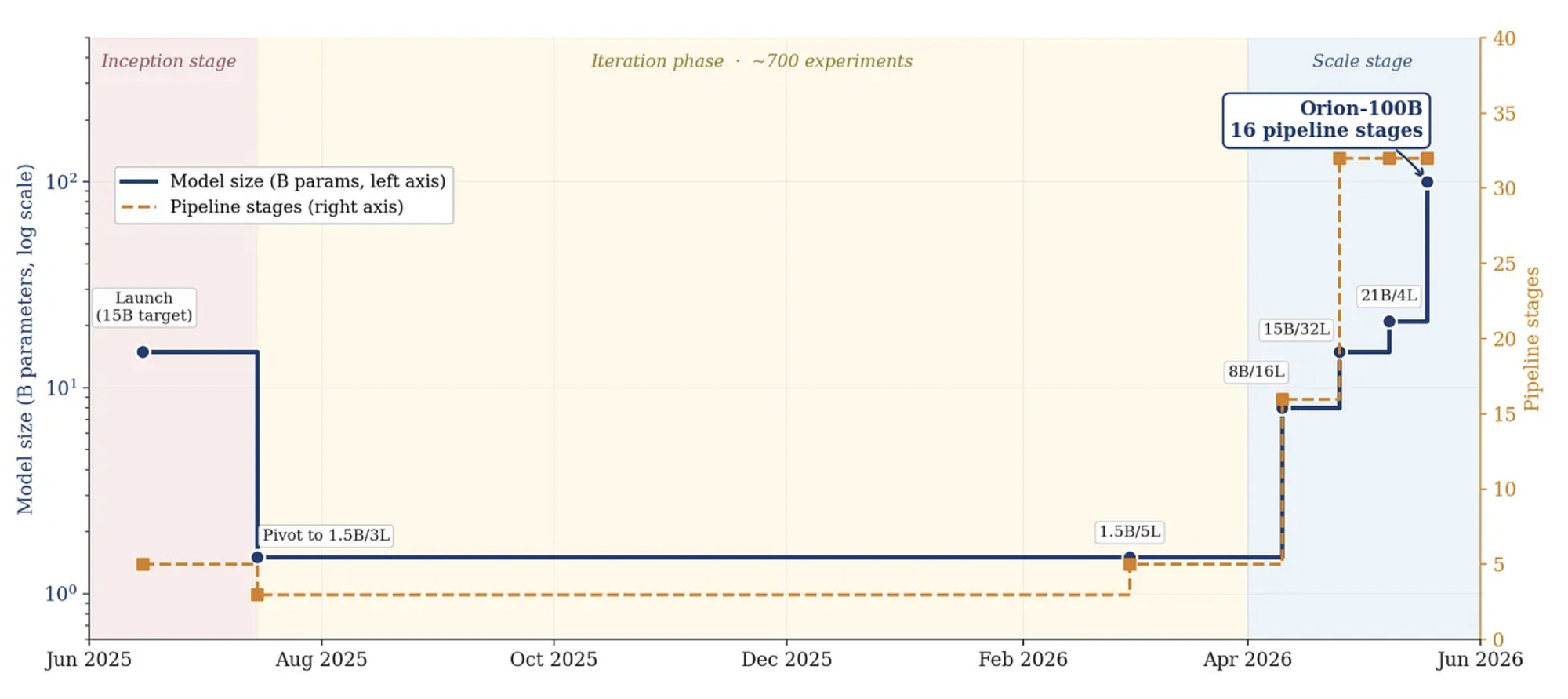
By April 2026, the team began rapidly increasing model size and pipeline complexity, ultimately scaling from 1.5 billion parameters to 100 billion parameters within roughly a month.
Key Technical Advances
Macrocosmos credits Orion-100B's performance to several technical breakthroughs developed during the project.
These include ResBM, which the team describes as a state-of-the-art lossless activation compression technique, a custom fault-tolerant peer-to-peer networking protocol designed for heterogeneous GPU environments, and distributed synchronization systems that allow training to continue even when individual nodes experience delays or interruptions.
These improvements increased training throughput by roughly an order of magnitude compared with earlier versions of the system.
During the Orion-100B run, activation transfers between pipeline stages were compressed from approximately 140 MB to 2.2 MB, significantly reducing networking overhead.
The Road to Permissionless Training
Orion-100B is, of course, not the final goal.
Project Orion is intended to progressively relax assumptions about the training environment, moving beyond controlled datacenter infrastructure toward heterogeneous hardware, interruptible compute, permissionless participation, and eventually consumer-grade machines.
Future stages of the project are expected to test training across mixed GPU fleets, spot-market hardware, third-party compute providers, and potentially home devices such as RTX 4090s and Apple Silicon systems.
The long-term objective is to create a training network where underutilized compute resources around the world can collectively function as frontier-scale AI infrastructure.
For Bittensor, Orion-100B represents one of the largest demonstrations to date of a subnet pursuing frontier AI research directly on the network, while advancing the broader thesis that decentralized infrastructure can compete with traditional approaches at meaningful scale.
Disclaimer: This article is for informational purposes only and does not constitute financial, investment, or trading advice. The information provided should not be interpreted as an endorsement of any digital asset, security, or investment strategy. Readers should conduct their own research and consult with a licensed financial professional before making any investment decisions. The publisher and its contributors are not responsible for any losses that may arise from reliance on the information presented.




{kind=link}