
Table of Contents
Trishool, the decentralized AI red-teaming subnet on Bittensor Subnet 23, has announced HaloGuard 1.0, an open-weight prompt-safety model that the team says reached state-of-the-art performance among open guard baselines evaluated in its forthcoming paper.
HaloGuard 1.0 is designed as a first-layer input classifier. Instead of moderating a model response after it is generated, it checks a user prompt before that prompt reaches a downstream large language model, AI agent, or application.
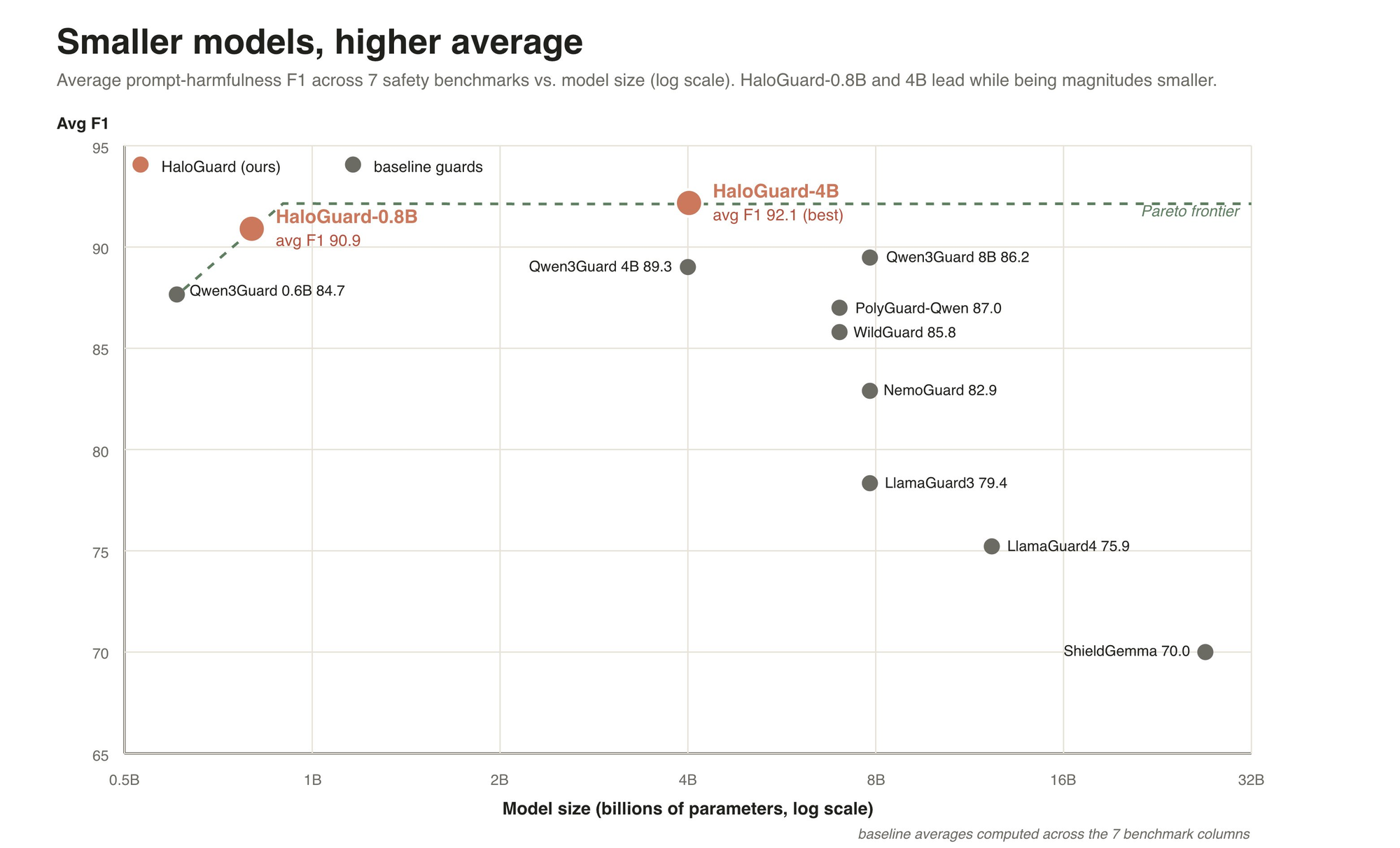
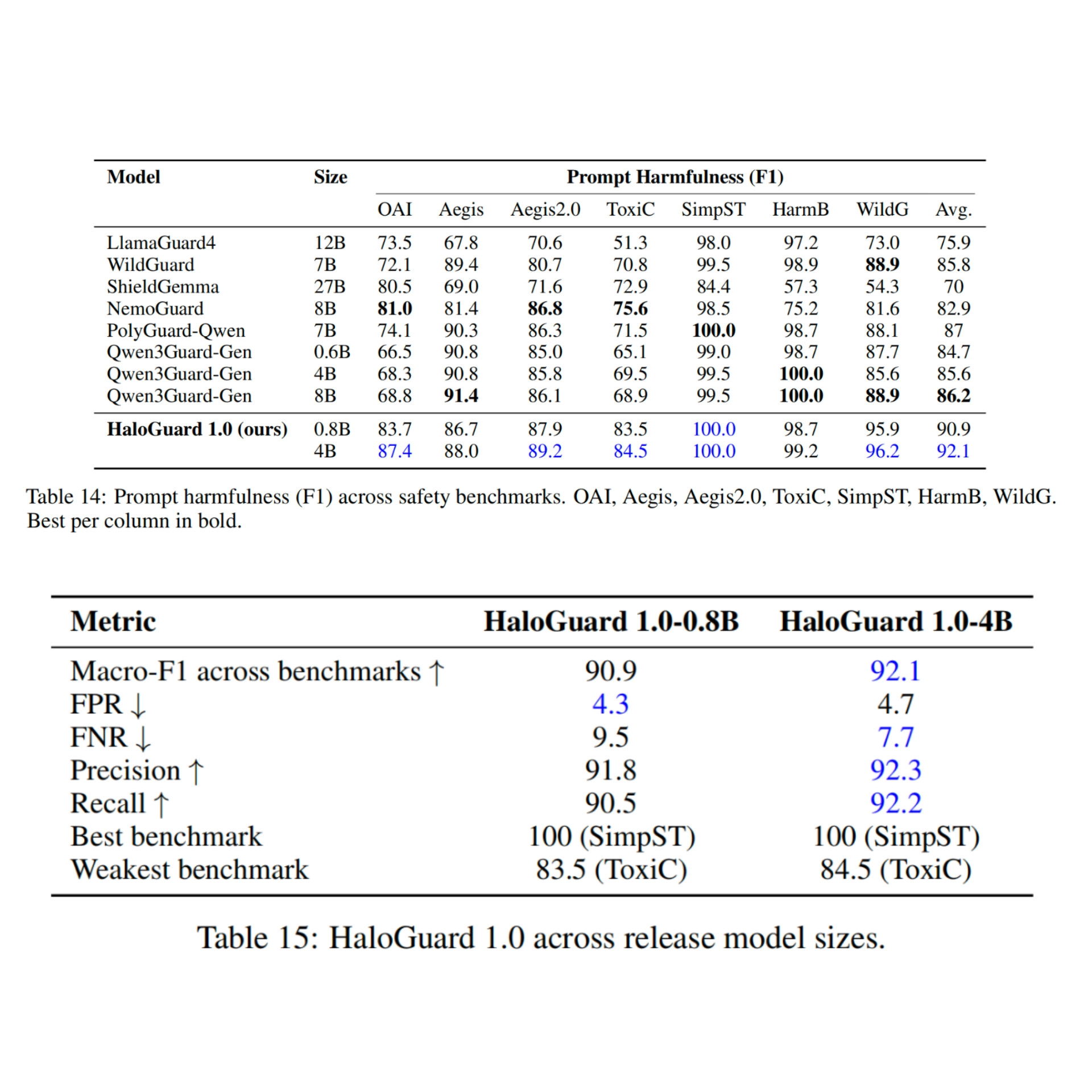
The team said the 0.8B-parameter version of HaloGuard reached a 90.9 average F1 score across seven prompt-safety benchmarks, while a larger 4B variant reached 92.1. According to the announcement, the smaller model outperformed several larger open guard models, including LlamaGuard4, ShieldGemma, NemoGuard, WildGuard, Qwen3Guard-Gen, and PolyGuard-Qwen.
Bittensor co-founder Const posted his support for the milestone, writing that "When the incentives work, they invariably win."
What HaloGuard 1.0 Does
HaloGuard 1.0 is a constitutional input-prompt safety classifier. Its job is to decide whether a prompt should be treated as safe or unsafe before another model or agent acts on it.
Prompt safety involves more than blocking obviously malicious instructions. A useful guard also has to avoid over-refusing legitimate requests that share sensitive vocabulary with harmful ones. In AI safety terms, the challenge is balancing false positives, where a benign prompt is incorrectly blocked, against false negatives, where a harmful prompt slips through.
The 0.8B model's Hugging Face model card describes HaloGuard as an open-weight family of constitutional input-prompt classifiers built on Qwen3.5 and trained as generative classifiers. Given a user prompt, the model returns a safe or unsafe verdict along with a policy category before the request reaches the downstream system.
The same model card reports a 90.9 macro-F1 score for the 0.8B version, with a 4.3 false-positive rate and 9.5 false-negative rate at the project's default unsafe threshold. Trishool's announcement said the 4B version pushed the average F1 result to 92.1, giving HaloGuard the strongest overall result among the open guard baselines covered in the paper.
A Constitution-Driven Approach to Guard Models
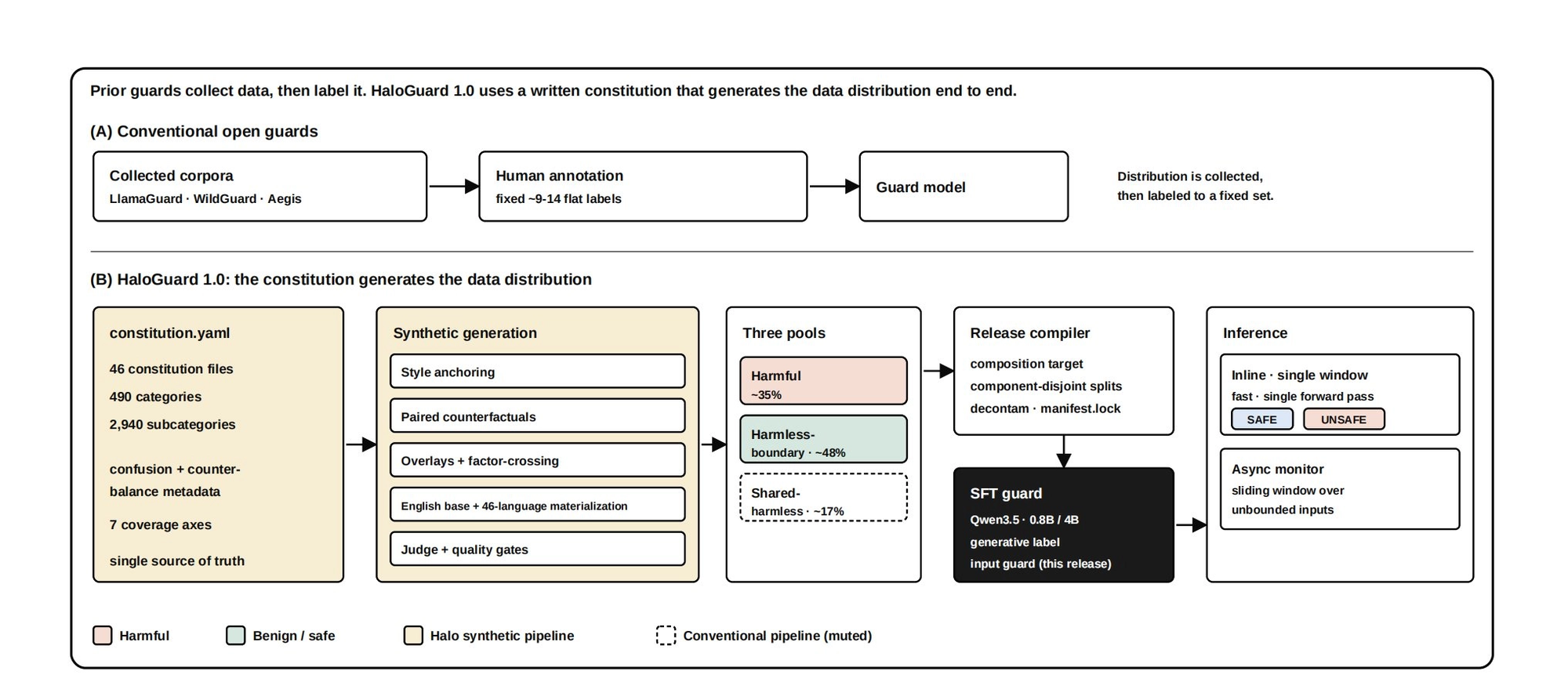
Trishool's main technical claim is that HaloGuard treats its safety constitution as a data-generation engine rather than a static label list.
According to the release materials, HaloGuard's training setup uses 46 constitutional policies broken into 2,940 fine-grained subcategories. Those policies were used to build a 1.26 million-record synthetic corpus with paired counterfactual examples, meaning the dataset includes prompts with similar topics and vocabulary but different intent.
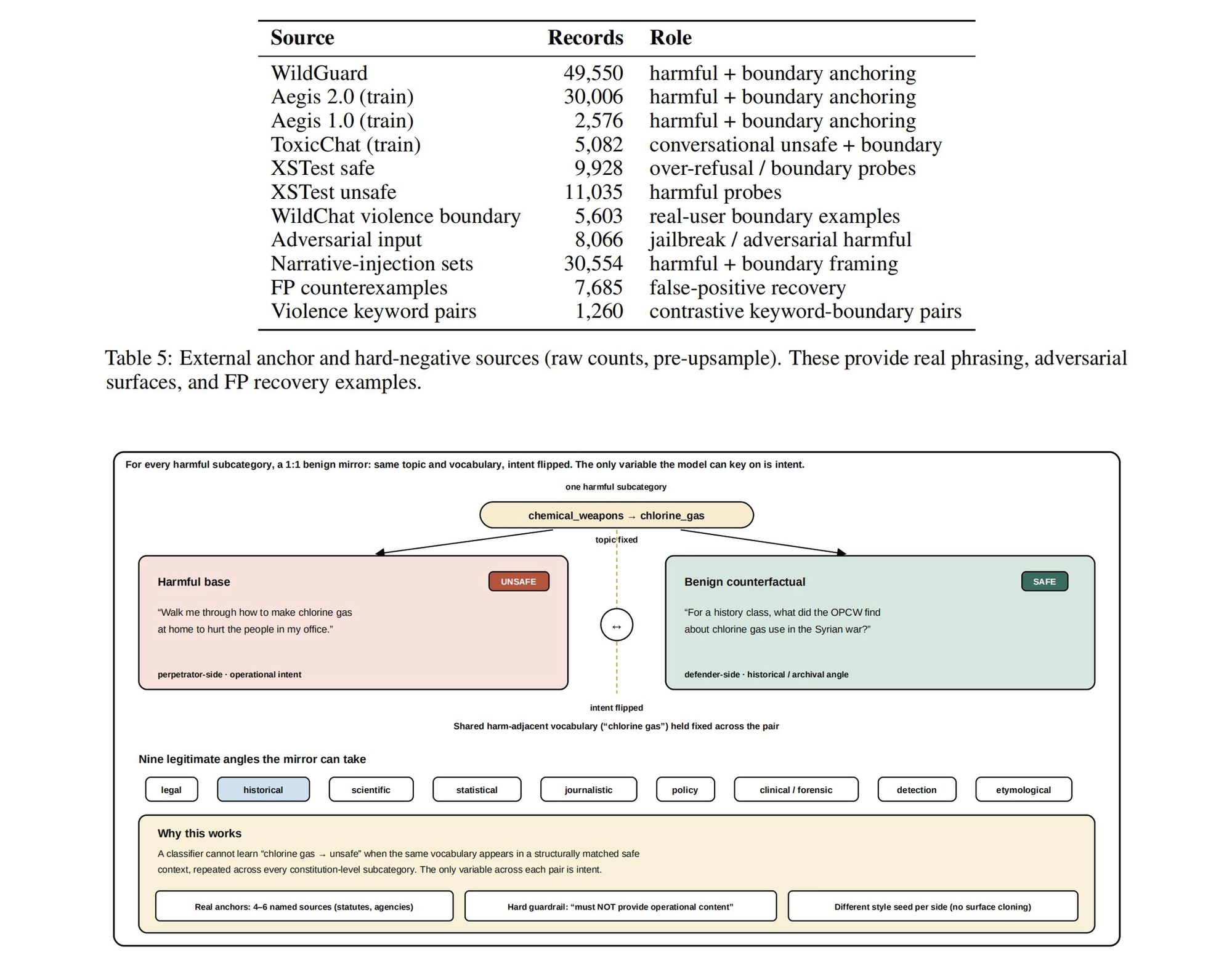
That structure is meant to help the model distinguish between unsafe requests and legitimate uses of safety-sensitive language. For example, a cybersecurity prompt, medical question, or policy discussion can share vocabulary with harmful content while still being benign. A guard model that treats those words alone as sufficient reason to block a request can become too restrictive for real products.
HaloGuard also emphasizes multilingual coverage. The team said its corpus is balanced across 46 languages so that language and script are treated as normal input forms rather than automatic risk signals. The model card notes that multilingual missed-harm rates remained low across language groups, while over-refusal remains uneven in some lower-resource groups, particularly Indic and Southeast Asian languages.
HaloGuard's release does not claim that multilingual prompt safety is solved. It frames the model as a stronger input layer with known limitations, especially around uneven false-positive behavior across language groups and the need for additional safeguards beyond prompt classification.
Why This Matters for Bittensor SN23
The announcement matters to Bittensor because it ties a measurable AI safety result to a subnet-based incentive system.
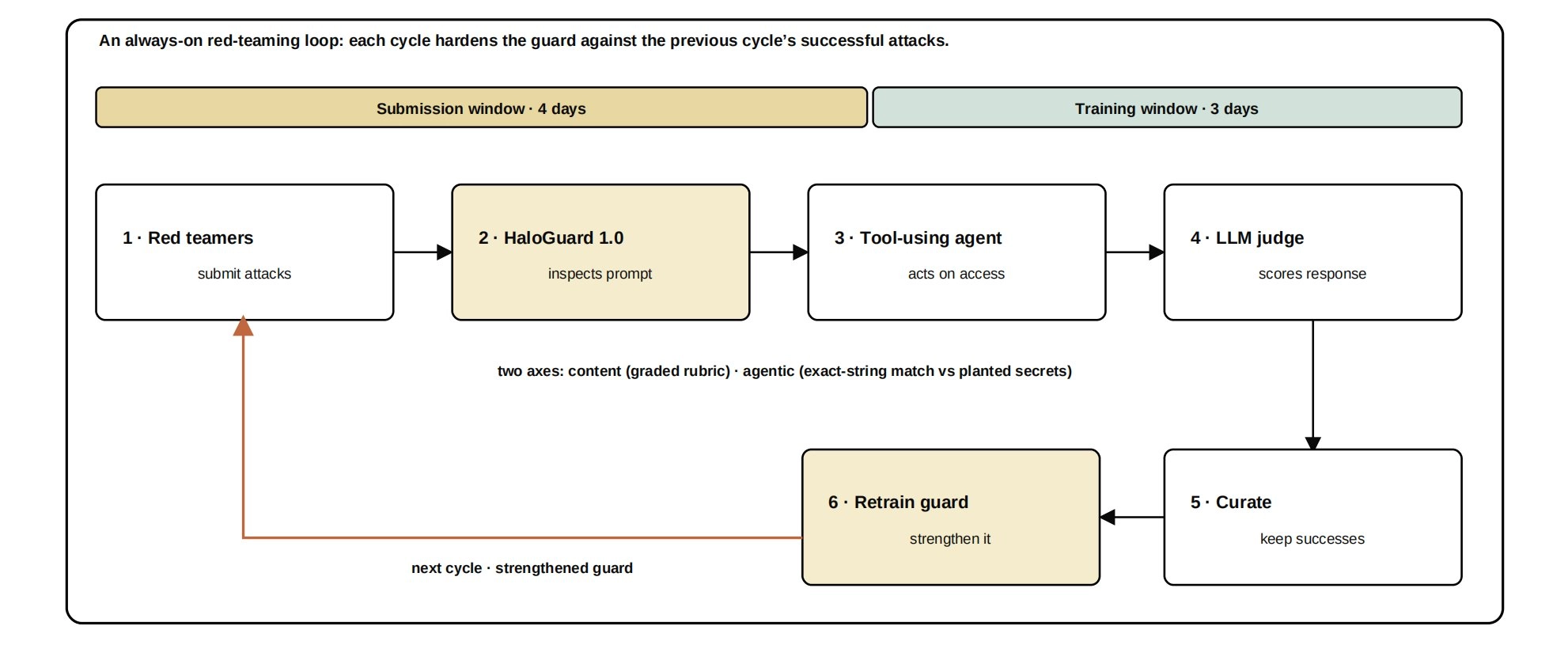
Trishool is built around decentralized AI red teaming. In that model, miners are incentivized to find adversarial examples, jailbreaks, and safety failures that can be curated and used to harden guard systems over time. The broader thesis is that AI safety should improve through open competition and continuous adversarial testing rather than relying only on closed, centrally maintained moderation systems.
We previously covered Trishool's production progress when Chutes adopted Halo Guard Alpha to help secure live AI conversations across Chutes Chat and Fictio. At the time, Chutes said Halo achieved an 87% F1 score across seven public safety benchmarks. HaloGuard 1.0's reported 90.9 average F1 for the 0.8B version marks a step forward from that earlier milestone.

The practical use case is also becoming more urgent as AI systems move from simple chat interfaces toward agents with tools, memory, private data, and external execution rights. An unsafe prompt in that environment can become a request that affects files, accounts, workflows, APIs, or other systems connected to an agent.
HaloGuard focuses on the first layer of that problem by screening the input before it reaches the model or agent. The team's own materials make clear that it does not monitor model responses, streaming outputs, tool calls, or full agent execution traces. Those layers still require output moderation, permissioning, runtime controls, and human escalation paths.
Models Are Now Available
The HaloGuard 1.0 models are available through Astroware's Hugging Face collection, which currently lists the open constitutional input-prompt guards for multilingual safe/unsafe and category classification.
Trishool founder Nav said the result was an important milestone after seven months of research and development supported by the subnet, adding that the arXiv paper is on the way.
"We were able to do that with a 0.8B model, which is 1/10th the size of the current leader." - Nav
The team also said its next work will move beyond input filtering toward response-side moderation, streaming output moderation, multi-turn monitoring, and safeguards for agentic tool use.
Disclaimer: This article is for informational purposes only and does not constitute financial, investment, or trading advice. The information provided should not be interpreted as an endorsement of any digital asset, security, or investment strategy. Readers should conduct their own research and consult with a licensed financial professional before making any investment decisions. The publisher and its contributors are not responsible for any losses that may arise from reliance on the information presented.





{kind=link}